
1 Welcome To The HashDig Project
HashDig technology is a collection of utilities designed to help
practitioners automate the process of resolving MD5 and SHA1 hashes.
In the early stages of an investigation, it is not typically
possible or practical to examine all subject files. Therefore,
practitioners need reliable methods that can quickly reduce the
number of files requiring examination. One such method is to group
files into two general categories: known and unknown. This method
can be implemented quite effectively by manipulating hashes and
comparing them to one or more reference databases. Even that,
however, can take a significant amount of effort. HashDig
technology attempts to reduce this burden through automation and the
use of lightweight, open, and verifiable techniques.
HashDig technology was designed to work in conjunction with FTimes
and is currently maintained and distributed under that project (click here for cvs access).
The name, HashDig, is reminiscent of the dig (domain information
groper) utility because it performs a type of resolution.
FTimes is a system baselining and evidence collection tool. The
primary purpose of FTimes is to gather and/or develop topographical
information and attributes about specified directories and files in
a manner conducive to intrusion and forensic analysis. FTimes is
available here.
2 Constructing Reference Databases
There are a number of different sources for obtaining known hashes.
The purpose of this section is to describe how to harvest these
sources and create reference databases using HashDig technology.
Any database that contains known hashes can be used as a reference.
However, it's best to construct reference databases such that
they only contain known hashes.
A HashDig database is an ordered list of MD5 or SHA1 hashes -- each
of which is tagged as known (K) or unknown (U). HashDig databases
are implemented as BTrees and constructed using Perl's DB_File
module. Enumerating these databases yields the following format:
hash|category
Ideally, reference databases should be proactively created and
regularly maintained. The payoff for this investment is realized
when you are called upon to investigate an intrusion or verify
the integrity of various files.
The most important investment you can make to speed hash resolution
is to create system baselines for all systems under your purview.
Ideally, this would be done before each system is deployed in an
operational environment. If these systems undergo a significant
amount of change, then it is equally important to take snapshots
on a regular basis. With tools like FTimes that were built to
operate on an enterprise scale, the cost of setting up an integrity
monitoring framework pales in comparison to the amount of time
it will take to resolve hashes where no prior baselines exist.
That being said, the remainder of this section is dedicated to
the task of creating reference databases from the various available
sources. Important sources for hash resolution include:
- National Software Reference Library (NSRL)
- Sun's Solaris Fingerprint Database
- HashKeeper
- KnownGoods
- Installation media, packages, and backups
Two critical assumptions, implicit in this approach, are that
these sources are untainted and their hashes correspond to known
good files. It is possible that a particular source contains
hashes that correspond to known bad files, but that would require
additional tags or separate handling to prevent confusion. This
document makes the assumption that all hashes harvested from
reference sources correspond to known good files.
2.1 National Software Reference Library (NSRL)
Information on the NSRL project and how to obtain NSRL data sets
is available here.
Over time, NSRL data sets will play an increasingly important
role in hash resolution -- to the point that best practices will
dictate their involvement in all but the most trivial cases.
To construct an MD5 reference database from NSRL data sets, run the
following commands:
hashdig-harvest.pl -c k -t nsrl1 -o nsrl.hd NSRLFile.txt
hashdig-make.pl -F -i -d nsrl.db nsrl.hd
Documentation on hashdig-harvest.pl and hashdig-make.pl can be
obtained by running perldoc on the respective files as follows:
perldoc hashdig-harvest.pl
perldoc hashdig-make.pl
As additional NSRL data sets are released, any new MD5 hashes can be
merged into the existing database (i.e., nsrl.db) by rerunning the
harvest and make utilities as follows:
hashdig-harvest.pl -c k -t nsrl1 -o nsrl.hd.new NSRLFile.txt.new
hashdig-make.pl -d nsrl.db nsrl.hd.new
2.1.1 NSRL Gotchas
Presently, hashdig-make.pl properly parses NSRL data sets, but
there is one known issue to keep in mind: The field separator for
NSRL data sets is a comma. The problem with this is that various
filenames in the data sets (e.g., ",jack.gif") also contain commas.
Unfortunately, this complicates parsing logic and makes it more
error prone. If you are processing NSRL data and observe errors
related to record parsing, inspect the offending record(s) to
determine if this issue applies.
Running the harvest script on millions of hashes takes a lot of
space. Consequently, your /tmp partition may fill up. By default,
/tmp is used as the temporary work area. This location can be
changed with the '-T' option.
Don't assume that all hashes in NSRL data sets are known good
hashes.
2.2 Sun's Solaris Fingerprint Database
Sun's online fingerprint database is available here.
To create an MD5 Sun reference database, you must first acquire some
hashes -- Sun's online interface does not allow you to request
hashes by filename.
One approach to this problem would be to baseline your Solaris
systems and resolve the collected hashes against Sun's online
database. Assuming the systems were baselined with FTimes and
the corresponding map files are located in ${MAPS}, then the
following set of commands can be used to construct a reference
database:
hashdig-harvest.pl -c u -t ftimes -o snapshot.hd ${MAPS}/*.map
hashdig-make.pl -F -i -d snapshot.db snapshot.hd
hashdig-dump.pl -c u -h snapshot.db | hashdig-resolve-sunsolve.pl -f -
hashdig-harvest-sunsolve.pl -c k -o sunsolve.hd sunsolve
hashdig-make.pl -F -i -d sunsolve.db sunsolve.hd
Documentation on these utilities can be obtained by running perldoc
on the respective files.
Each time you sling new hashes against Sun's online database, you
should take time to merge any resolved MD5 hashes into your existing
reference database (i.e., sunsolve.db). Assuming the newly resolved
hashes are in sunsolve.hd.new, this can be done as follows:
hashdig-make.pl -d sunsolve.db sunsolve.hd.new
As a side note, slinging hashes collected from other OSes against
Sun's online database can yield useful results.
2.3 HashKeeper
To create an MD5 HashKeeper reference database, you must first
download some hash sets, which may be difficult to do these days.
Assuming the hash sets you downloaded are located in ${HKS}, then
the following commands can be used to construct a reference
database:
hashdig-harvest.pl -c k -t hk -o hk.hd ${HKS}/*.hsh
hashdig-make.pl -F -i -d hk.db hk.hd
As additional hash sets are released, any new MD5 hashes can be
merged into the existing database (i.e., hk.db) by rerunning the
harvest and make utilities as follows:
hashdig-harvest.pl -c k -t hk -o hk.hd.new ${HKS}/*.hsh.new
hashdig-make.pl -d hk.db hk.hd.new
2.3.1 HashKeeper Gotchas
See NSRL Gotchas.
2.4 KnownGoods
KnownGoods hash sets are available here.
To create an MD5 KnownGoods reference database, you must first
download some hash sets. Assuming the hash sets you downloaded are
located in ${KGS}, then the following commands can be used to
construct a reference database:
hashdig-harvest.pl -c k -t kg -o kg.hd ${KGS}/*.txt
hashdig-make.pl -F -i -d kg.db kg.hd
As additional hash sets are released, any new MD5 hashes can be
merged into the existing database (i.e., kg.db) by rerunning the
harvest and make utilities as follows:
hashdig-harvest.pl -c k -t kg -o kg.hd.new ${KGS}/*.txt.new
hashdig-make.pl -d kg.db kg.hd.new
2.4.1 KnownGoods Gotchas
See NSRL Gotchas.
2.5 Installation Media, Packages, and Backups
Installation media, packages, and backups, if trusted and untainted,
can play a major role in hash resolution. This is because they
are more likely to contain files that actually exist on subject
systems.
The standard approach for building a reference database from
installation media or packages would be to install them on a clean
system, baseline the installed files with FTimes, and run the
HashDig make utility on the resulting map data. In some cases,
it may not be necessary to install the media/package. For example,
if the media/package was distributed as a tar ball or zip file,
then simply unpacking it in a clean directory would suffice for
the first step.
With backups, the basic process is the same except that backups
need only to be restored in a clean directory. With backups,
however, one must be confident that the attackers have not become
entrenched in the backup process.
Assuming the maps you collected for installation media, packages,
and backups are located in ${MAPS}, then the following commands
can be used to construct an MD5 reference database:
hashdig-harvest.pl -c k -t ftimes -o site.hd ${MAPS}/*.map
hashdig-make.pl -F -i -d site.db site.hd
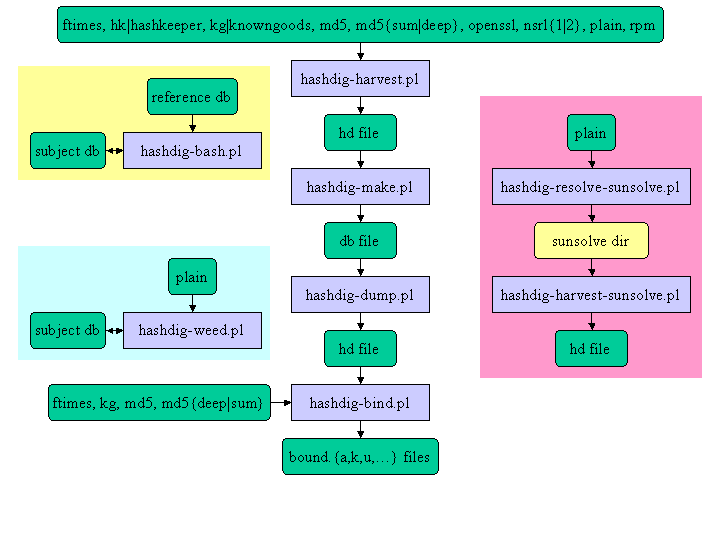
3 Hash Resolution Work-Flow
At a high level, the hash resolution work-flow roughly consists
of the following steps:
- Harvesting Subject Hashes
- Subject Database Construction
- Subject Database Bashing
- Binding Subject Hashes Back to Filenames
- Sorting and Filtering
The following sub-sections discuss these steps in more detail.
Click here to view a
diagram that depicts the various HashDig utilities and the
input/output data types they consume/produce.
3.1 Harvesting Subject Hashes
The hash resolution work-flow begins by harvesting all unique,
subject hashes relevant to your investigation and tagging them
as unknown. Typically, these hashes would come from FTimes map
data, but they could also come from a number of other sources
such as md5, md5deep, md5sum, and so on. Assuming that your map
files are located in ${MAPS}, then the following command would
be used to harvest the subject hashes:
hashdig-harvest.pl -c u -t ftimes -o subject.hd ${MAPS}/*.map
Note: If you are processing SHA1 hashes, you'll either need to set
the HASH_TYPE environment variable or use the '-a' command line
argument. See the man page for details.
3.2 Subject Database Construction
Once hashes have been harvested, the subject database can be
constructed. This would be done with the following command:
hashdig-make.pl -F -i -d subject.db subject.hd
Note: If you are processing SHA1 hashes, you'll either need to set
the HASH_TYPE environment variable or use the '-a' command line
argument. See the man page for details.
Keep a backup of this database for future reference as subsequent
steps will alter its contents.
cp subject.db subject.db.orig
3.3 Subject Database Bashing
Next, subject hashes are bashed against (compared to) existing
reference databases (e.g., nsrl.db, sunsolve.db, hk.db, kg.db,
site.db, etc.) -- these are databases that you create and maintain.
As hashes in the subject database are resolved, their category
information is updated. The primary rule of engagement is that
known hashes trump unknown hashes. In shell speak this process
takes on the following form:
for i in "nsrl.db" "sunsolve.db" "hk.db" "kg.db" "site.db" ; do
hashdig-bash.pl -r $i -s subject.db
done
3.3.1 Harvesting Online Resources
At this point, all existing reference sets have been exhausted.
If necessary and appropriate, any remaining unknown hashes should
be submitted to Sun's online fingerprint database for resolution.
The HashDig way to do this is as follows:
hashdig-dump.pl -c u -h subject.db | hashdig-resolve-sunsolve.pl -f -
Hashes resolved by Sun should be harvested and placed in a temporary
reference database.
hashdig-harvest-sunsolve.pl -c k -o sunsolve.tmp.hd sunsolve
hashdig-make.pl -F -i -d sunsolve.tmp.db sunsolve.tmp.hd
Then, subject hashes are bashed again.
hashdig-bash.pl -r sunsolve.tmp.db -s subject.db
After the bashing is complete, the temporary HashDig file should
be merged into your existing reference database.
hashdig-make.pl -d sunsolve.db sunsolve.tmp.hd
3.4 Binding Subject Hashes Back to Filenames
When all reference databases have been exhausted, hashes in the
subject database are rebound to the map files from whence they
came.
hashdig-dump.pl subject.db | hashdig-bind.pl -t ftimes -f - ${MAPS}/*.map
Note: If you are processing SHA1 hashes, you'll either need to set
the HASH_TYPE environment variable or use the '-a' command line
argument. See the man page for details.
3.5 Sorting and Filtering
As a followup step, the practitioner may decide that it's necessary
or desirable to sort or filter the output in different ways. One
approach for narrowing the list of unknowns is to filter the data
according to directory type (i.e., bin, dev, etc, lib, and man).
hashdig-filter.pl *.bound.u
4 Supported File Formats
Currently, hashdig-harvest.pl supports the following formats:
FTIMES, FTK, HK|HASHKEEPER, KG|KNOWNGOODS, MD5, MD5DEEP, MD5SUM,
OPENSSL, NSRL1, NSRL2, PLAIN, RPM, SHA1, SHA1DEEP, and SHA1SUM. Of
these, hashdig-bind.pl supports the following formats: FTIMES, FTK,
KG|KNOWNGOODS, MD5, MD5DEEP, MD5SUM, OPENSSL, SHA1, SHA1DEEP, and
SHA1SUM. The only format supported by hashdig-make.pl is HASHDIG.
Details regarding each supported format are discussed in the
following sections.
4.1 FTimes
Any FTimes map data that contains, at a minimum, the name and md5
fields is supported. However, when processing map data collected
from UNIX systems, it is helpful to include the mode field as it
is used to filter out symlink hashes -- generally, symlink hashes
are not used during hash resolution.
Here's an example invocation (--mapauto mode):
ftimes --mapauto all-magic /sbin /usr/bin /usr/sbin
Here's the minimum FTimes format (i.e., FieldMask=none+md5):
name|md5
Here's the typical UNIX format (i.e., FieldMask=all-magic):
name|dev|inode|mode|nlink|uid|gid|rdev|atime|mtime|ctime|size|md5|sha1|sha256
Here's the typical WIN32 format (i.e., FieldMask=all-magic):
name|volume|findex|attributes|atime|ams|mtime|mms|ctime|cms|chtime\
|chms|size|altstreams|md5|sha1|sha256
Note that filenames in FTimes output are and URL encoded. Therefore,
it may be necessary to insert a URL decoding stage at the appropriate
point in your work-flow. The following code snippet is a Perl
subroutine that does this type of decoding:
sub URLDecode
{
my ($rawString) = @_;
$rawString =~ s/\+/ /sg;
$rawString =~ s/%([0-9a-fA-F]{2})/pack('C', hex($1))/seg;
return $rawString;
}
4.2 FTK
The FTK format refers to reference data sets distributed by the
Forensic Toolkit.
Here's the FTK format (presented vertically):
File Name
Full Path
Recycle Bin Original Name
Ext
File Type
Category
Subject
Cr Date
Mod Date
Acc Date
L-Size
P-Size
Children
Descendants
Enc
Del
Recyc
Idx
Sector
Cluster
Alt Name
Dup
RO
Sys
Hid
Item #
Cmp
KFF
Badxt
Emailed
Header
MD5 Hash
SHA Hash
Hash Set
Email Date
From
To
CC
Attachment Info
FTK fields are tab delimited.
4.3 HashDig
The HashDig format refers to data generated by hashdig-dump.pl,
hashdig-harvest.pl, or hashdig-harvest-sunsolve.pl.
Here's the HashDig format:
hash|category
Here's the reverse HashDig format:
category|hash
4.4 HashKeeper
The HashKeeper format refers to reference data sets distributed
by the HashKeeper project and the National Software Reference
Library (2.X series).
Here's the HashKeeper format (presented vertically):
file_id
hashset_id
file_name
directory
hash
file_size
date_modified
time_modified
time_zone
comments
date_accessed
time_accessed
HashKeeper fields are comma delimited.
4.5 KnownGoods
The KnownGoods format refers to reference data sets distributed
by the Known Goods project.
Here's the KnownGoods format as of 2003-03-25:
ID,FILENAME,MD5,SHA-1,SIZE,TYPE,PLATFORM,PACKAGE
4.6 MD5
The MD5 format refers to data collected with the md5 utility that
is distributed with FreeBSD.
Here's an example invocation:
find /sbin /usr/bin /usr/sbin -type f -exec md5 {} \;
Here's the MD5 format:
MD5 (name) = hash
4.7 MD5Deep
The MD5Deep format refers to data collected with the md5deep
utility which is located here.
Here's an example invocation:
md5deep -r /sbin /usr/bin /usr/sbin
Here's the MD5Deep format:
hash name
4.8 MD5Sum
The MD5Sum format refers to data collected with the md5sum utility
that is distributed with Linux.
Here's an example invocation:
find /sbin /usr/bin /usr/sbin -type f -exec md5sum {} \;
Here's the MD5Sum format:
hash name
4.9 NSRL1
The NSRL1 format refers to reference data sets distributed by the
National Software Reference Library (1.X series).
Here's the NSRL1 format:
SHA-1,FileName,FileSize,ProductCode,OpSystemCode,MD4,MD5,CRC32,SpecialCode
4.10 NSRL2
The NSRL2 format refers to reference data sets distributed by the
National Software Reference Library (2.X series).
Here's the NSRL2 format:
SHA-1,MD5,CRC32,FileName,FileSize,ProductCode,OpSystemCode,SpecialCode
4.11 OpenSSL
The OpenSSL format refers to data collected with the openssl
utility which is located here.
Here's an example invocation:
find /sbin /usr/bin /usr/sbin -type f -exec openssl md5 {} \;
Here's the OpenSSL format for MD5s:
MD5(name)= hash
Here's the OpenSSL format for SHA1s:
SHA1(name)= hash
4.12 Plain
The Plain format refers to input that consists of one MD5 hash
per line.
Here's the Plain format:
hash
4.13 RPM
The RPM format refers to input created using RPM's query mode in
conjunction with its dump option.
Here's an example query:
rpm -q -a --dump
Here's the RPM format:
path size mtime md5sum mode owner group isconfig isdoc rdev symlink
4.14 SHA1
The SHA1 format refers to data collected with the sha1 utility that
is distributed with FreeBSD.
Here's an example invocation:
find /sbin /usr/bin /usr/sbin -type f -exec sha1 {} \;
Here's the SHA1 format:
SHA1 (name) = hash
4.15 SHA1Deep
The SHA1Deep format refers to data collected with the sha1deep
utility which is located here.
Here's an example invocation:
sha1deep -r /sbin /usr/bin /usr/sbin
Here's the SHA1Deep format:
hash name
4.16 SHA1Sum
The SHA1Sum format refers to data collected with the sha1sum utility
that is distributed with Linux.
Here's an example invocation:
find /sbin /usr/bin /usr/sbin -type f -exec sha1sum {} \;
Here's the SHA1Sum format:
hash name
5 Requirements
For the various HashDig scripts to work properly, Perl, sort, and
the following Perl modules: DB_File, File::Basename, FileHandle,
Getopt::Std, and IO::Socket must exist on the target system.
However, not all modules are required for each script, and sort
is only required for the harvest scripts.
Any system that runs hashdig-resolve-sunsolve.pl must be able to
make HTTP connections to Sun's Solaris Fingerprint Database.
Creating HashDig databases and binding hashes can quickly exhaust
all available memory. As a general rule, assume that each block
of 1 million hashes consumes roughly 32 MB of RAM.
HashDig scripts were designed to run in UNIX environments. Using
them in other environments is not supported at this time.
6 License
All HashDig documentation and code is distributed under same terms
and conditions as FTimes.
|





{kind=link}